If you studied economics at any point or have used Excel you probably know what linear regression is. It is extremely useful. In order to understand it better, we are going to go on a (non-rigorous) journey through finding the two coefficients for linear regression on one variable with a toy dataset.
We are going to calculate the coefficients for linear regression with one variable by:
- Trying various coefficients and seeing which is optimal
- Finding an exact solution
- Finding a precise-enough solution numerically with gradient descent
I like to think that in a parallel universe, this is how Keith Richards is explaining linear regression.
1. Trying various coefficients and seeing which are best
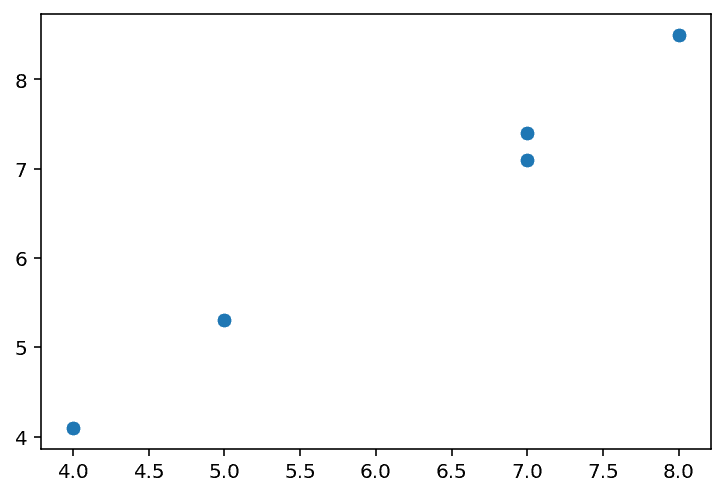
Let’s plot some random numbers for , and use those same numbers with a bit of jitter for , so we have an approximately linear relationship.
x, y
---
[[7. 7.4]
[4. 4.1]
[8. 8.5]
[5. 5.3]
[7. 7.1]]
In high school we were told that the equation of a straight line was , and that linear regression is the line in this form which ‘best fits’ the data we have for .
Now we’re in machine learning land let’s use , where are the intercept and the gradient respectively. The hat in denotes that it is an estimate, and the points along the regression line will be .
We need some way to come up with ; let’s call this .
And so .
Note that rather than regarding as our prediction for , we can regard it as the that goes with the obligatory on the linear regression line.
So far so good, but we have no idea how will work to supply us with our values which are sensible. One way to do this is to define how we will know when has done the optimal job for us. We know that this will be when the line best fits the data and we know that will be an input into our function that supplies us with . We also know that is parameterised by and , so really all we have to do is pick the best values for each of those.
Luckily for us, we have this function on hand. We will calculate the mean squared error (MSE) and we will denote this as the function . will be evaluated, and the lower the output (the MSE), the better. We call our ‘loss’ function, because we want to find the values for that minimise it.
The MSE is simply the mean of the square of all the errors, where the error is defined as for the pair of values at index i.e. for any given pair in our dataset. This is then also halved by convention, which has no effect on where the minimum or maximum are.
All we have to do now is minimise . To do this, let’s first take a brute force approach, plugging in values and seeing what that looks like. This approach of minimising is called ordinary least squares (OLS).
OLS has a couple of nice properties: a perfect fit will give us , and there will be one minimum, so we will be able to land on one set of parameters.
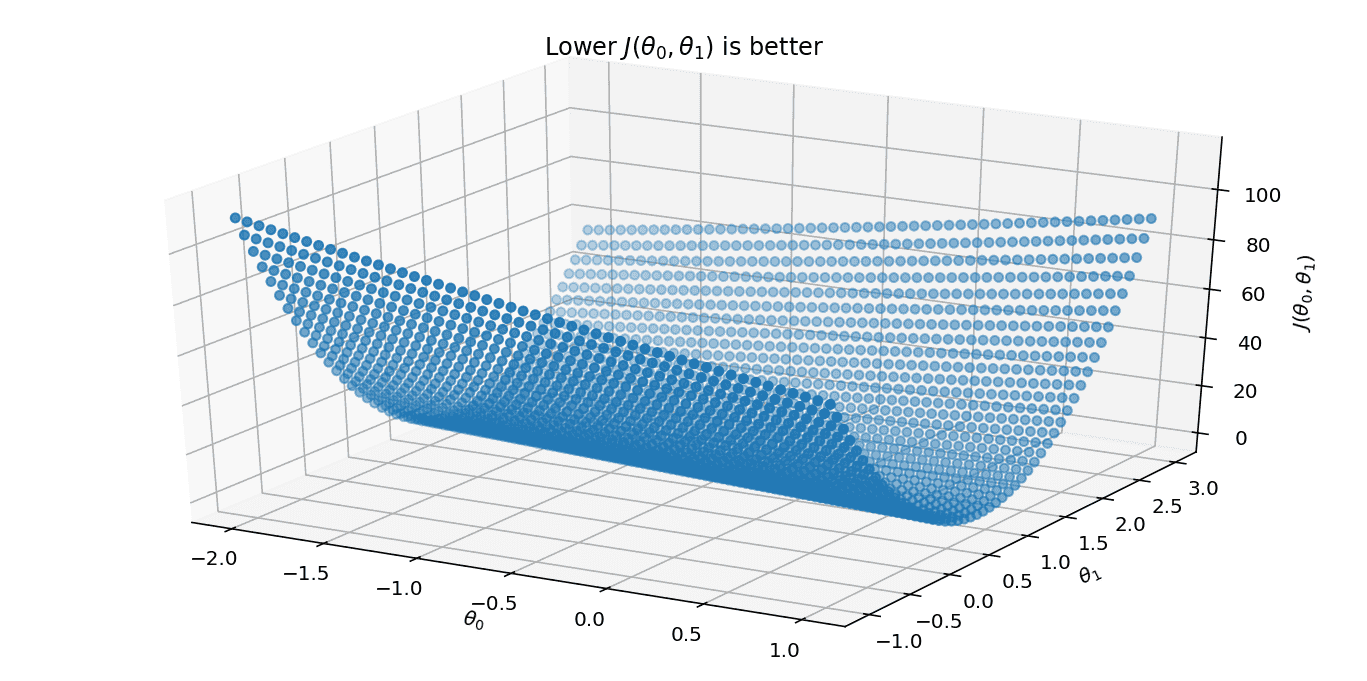
Such a chart is not that easy to read the values from, but that’s ok because we can ask the computer what the best values for are:
(0.020408163265305923, 1.0408163265306123)Let’s plot as our trend line given those values of and see how it looks.
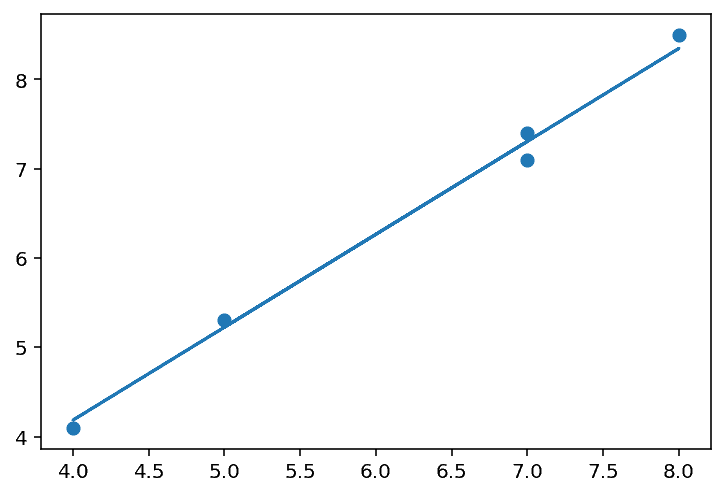
Not bad! But it doesn’t look exactly right. Maybe there is a better way to find these parameters for our trend line.
2. A. Finding an exact solution
We can find an exact solution using the magic of linear algebra and particularly matrix inversion.
By evaluating the right hand side of the above, we are left with a vector which contains our coefficients.
This is nice because it is quick for the computer to calculate, although it won’t always be possible to use this method because not all matrices can be inverted.
To do this, we first need to prepend a column vector of s to our column vector to create a matrix . This means that when we do our calculations, we will end up with a value for in addition to .
We will be working with:
y =
[[7.4]
[4.1]
[8.5]
[5.3]
[7.1]]
X =
[[1 7]
[1 4]
[1 8]
[1 5]
[1 7]]Which gives us for
[[-0.133]
[ 1.067]]
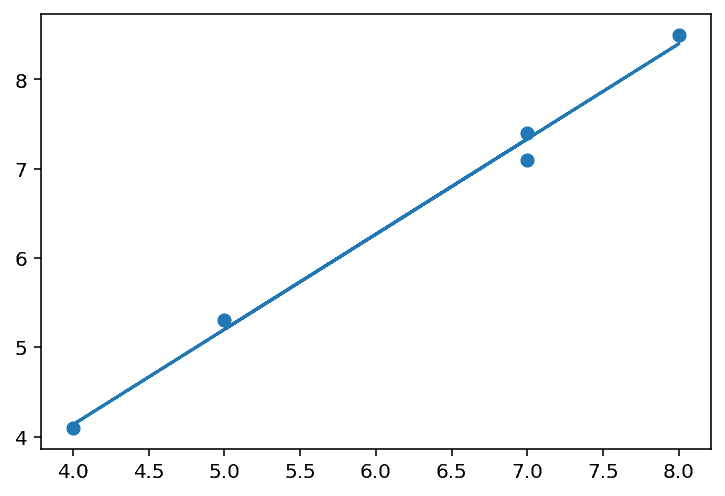
When we plot the regression line with these it looks pretty good.
2. B. Finding an exact solution (again)
We know that we want to find the minimum of our loss function with respect to parameters … which sounds a lot like a calculus problem. We will not always be able to invert the matrix per the previous, and this will give us an exact solution.
We can take the partial derivative of with respect to each of and set each of these to 0.
[ … ]
And this gives us the same answer …
[-0.133 1.067]
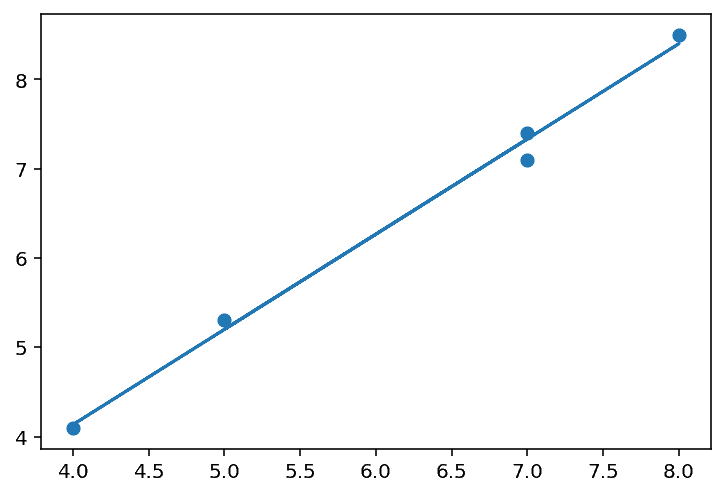
These provides us with a chart which looks reassuringly similar.
3. Gradient descent
We can also find the optimal values for using gradient descent.
To do this, we first set them to some arbitrary values, and then alter them based on the effect on .
More precisely, we pick a value for , the learning rate, which is kept constant and used to control the magnitude of the update. We subtract from our given parameter . We do this for each . We then repeat this exercise, and as we get closer to the optimal values, the subtracted value reduces in magnitude, until such time as any barely changes at all.
Note that in the above means ‘is assigned the value of’. Further, both of need to be updated before the process is repeated.
If this sounds a bit similar to Newton-Raphson from school days, it is.
If we initialise both to one, the below chart shows their convergence towards the optimal value.

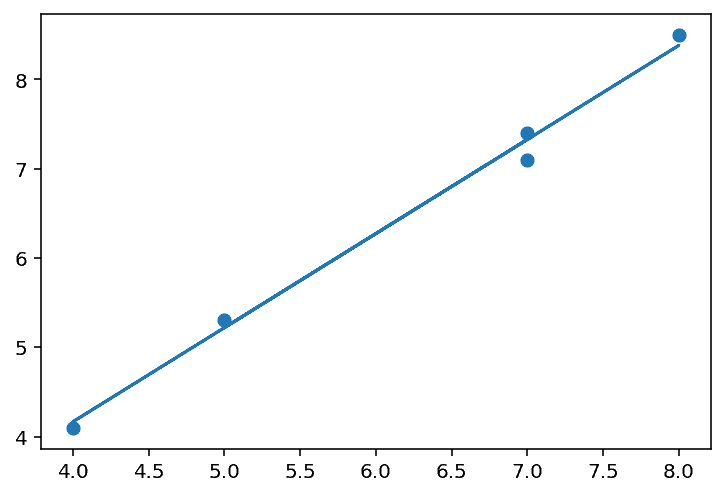
Looks reassuringly similar, again.
Notes
Notation
-
is an ‘input’ variable a.k.a. feature
-
is an ‘output’ variable a.k.a. target
-
Pair is a training example
-
List of training examples for is a training set
-
Note: is simply an index and not to do with exponentiation

“I’ll just run the numbers once I finish my Jack Daniels”